
Oct 17, 2023 • 4 min read
Revamping Privacy Mode: A Better Way to Obfuscate Sensitive Data

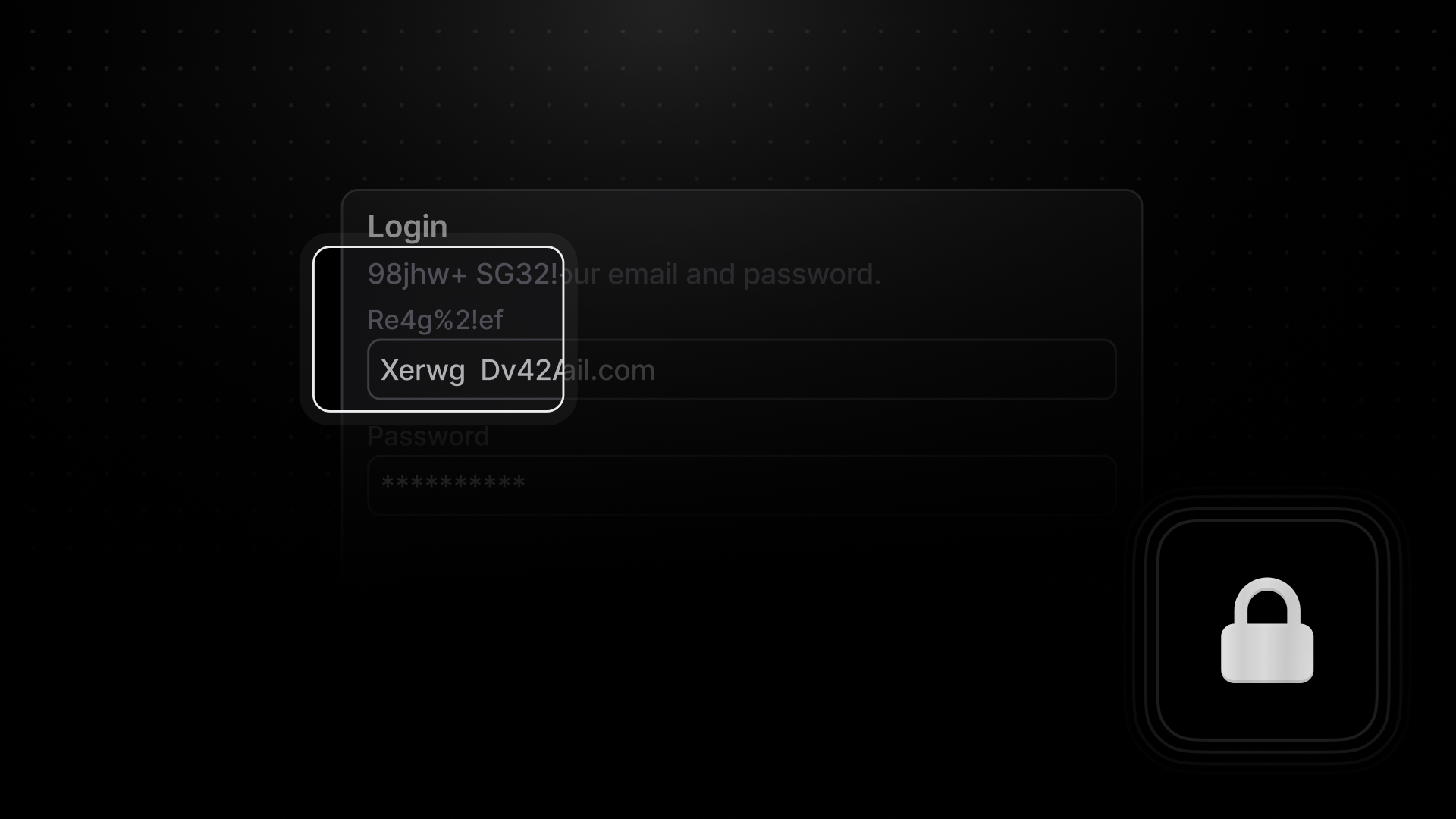
Do you enjoy seeing the code responsible for causing an error on your frontend stack traces? Do
As a b2b company with several customers who are quite sensitive about data protection and
information security, we built strict privacy mode several months ago. Strict privacy mode will
obfuscate all text in the DOM, not differentiating between sensitive and innocuous data. This is
irreversible, as the text is removed on client side, and Highlight will never receive this data.
For example, Highlight will receive <h1>Hello World</h1> as <h1>1f0eqo jw02d</h1>.
Previously, this mode was all or nothing, and there was little support to intelligently hide your personal information. Today we're excited to announce "default" privacy mode. As the name suggests, this mode will be enabled by default on SDK versions 8.0.0 and later. Default mode offers a smart level of privacy by obfuscating text that matches names and patterns associated with common personal identifiable information.
Default privacy mode relies on regex expressions to identify this data, such as phone numbers, social security numbers, email addresses, and more. This works well for static text, but is not helpful for dynamic text, like inputs. If a user is typing in a social security number, it may not get recognized until the first 8 digits are exposed. To solve this, we search the DOM for inputs with common names, ids, and autocomplete values, to obfuscate the input from the start.
Default privacy mode is a best effort algorithm, but is imperfect in a couple ways. First, it may
over obfuscate text that matches one of the regex expressions. In the example above, the UserId
matches a long number regex expression, designed to catch phone numbers. We expect this to
over-obfuscate certain texts, since there is no context being used to determine the "identifiable"
aspect of data. Determining context is difficult to do in real time, but an improvement area we are
looking into. Second, text broken up by different elements may not be obfuscated, despite the overall
text being recognized by a regex expression. For example, <div>spencer@<b>highlight</b>.io</div>
matches the email regex, but is broken up by a bold element. While this algorithm is not flawless, we
believe this solution is a great option for companies that want to minimize exposing data without going
the nuclear option. It represents a significant step forward in helping you safeguard your customer
data, and we are looking forward to improving and building additional privacy options. For any questions
or comments, don't hesitate to reach out to us on discord.



